Neural Networks from Scratch — part 1 The neuron

Welcome to the fascinating world of neural networks! These systems mimic how our brains process information, enabling technologies like facial recognition and language translation. In this series of blogs, we’ll build a neural network from scratch. Let’s start with the basics by creating a single neuron. Here is the link to the notebook containing all the code: Notebook
Prerequisites
A basic familiarity with partial derivatives and Python is expected (numpy)
Introduction to neural networks
Think of a neural network as a complex function. It takes in numbers as inputs, processes them, and produces the desired output. Unlike classic functions, neural networks have ‘parameters’ — values that the inputs are multiplied and added to. We don’t know these values at the start, and ‘training’ the network means figuring them out.
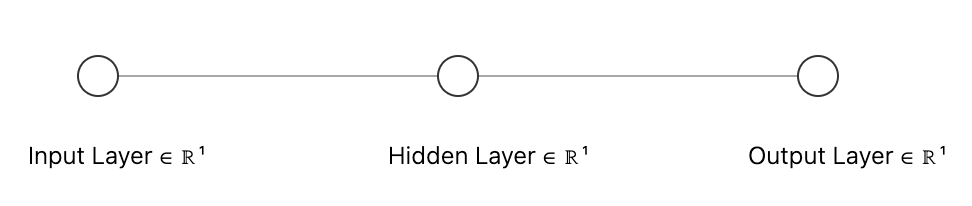
A neural network has 3 types of layers:
- Input Layer: Receives the inputs.
- Hidden Layers: Process the data.
- Output Layer: Produces the final output.
Here are a few additional areas that could be improved for clarity and readability:
Introduction
Current:
- “Welcome to the world of neural networks! These systems mimic how our brains process information, powering technologies like facial recognition and language translation. In this series of blogs, we’ll go from ground up in creating a neural network. In this blog, we begin with the simplest possible NN — a single neuron.”
Improved:
- “Welcome to the fascinating world of neural networks! These systems mimic how our brains process information, enabling technologies like facial recognition and language translation. In this series of blogs, we’ll build a neural network from scratch. Let’s start with the basics by creating a single neuron.”
Explanation of Neural Networks
Current:
- “Think of a neural network like a function. A massive function that takes in a bunch of numbers as inputs, processes them in different ways, and produces the output we need. What sets NNs apart from classic functions is that NNs have what we call “parameters”. These parameters are numbers that the inputs get multiplied and added to, but we don’t know what they are at the start. The job of “training” a network is to find out what these parameters are.”
Improved:
- “Think of a neural network as a complex function. It takes in numbers as inputs, processes them, and produces the desired output. Unlike classic functions, neural networks have ‘parameters’ — values that the inputs are multiplied and added to. We don’t know these values at the start, and ‘training’ the network means figuring them out.”
Types of Layers
A neural network consists of three types of layers:
- Input Layer: Receives the inputs.
- Hidden Layers: Process the data.
- Output Layer: Produces the final output.
In our code, we’ll focus on the hidden layer where all the processing happens, as the input and output layers mainly serve to hold numbers.
To make it easy to get started, we’ll tackle a very basic problem — linear regression. Given a set of data points, our job is to figure out a straight line through them.
Let us prepare the data first:
import numpy as np
x = np.array([i for i in range(1, 11)])
y = 2*x + 6Here, we’ve generated 10 numbers from 1 to 10 and calculated the y-values using the equation y=2x+6. This is how our line looks:

Here is our aim:
To make a neural network such that if given any x value, it can accurately predict the y value. Remember that the network doesn’t have access to the equation of the line; all it sees is input and output. Its job is to figure out the equation.
Right now, our network will consist of just 1 neuron. This neuron will look like a function:
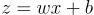
If you haven’t noticed, that’s the equation of the straight line:
- x is the number we will input
- w is called the weight; it plays the same role as the slope of the line
- b is called the bias; it plays the same role as the intercept of the line
Our job is to get the right weight and bias so that our neuron’s answer (z) matches the real y.
Here’s our thought process:
- We will randomly initialize the weight and the bias
- We will predict the value of y using that weight and bias
- We will figure out how wrong we are
- We will adjust our weight and bias based on how wrong we are
- We repeat the above 3 steps until we get an accurate model.
Let’s start with the first two steps:
class Neuron:
def __init__(self):
# Initializing random weight and bias
self.w = np.random.randn(1)
self.b = np.random.randn(1)
def forward(self, x):
# Storing the x value for later use
self.x = x
# Equation of straight line
self.z = self.x * self.w + self.b
return self.zIn the code above, we initialize random values for the weight and bias. The forward function takes an input value x, applies the equation, and returns the output.
Let’s test it:
Keep in mind that since these are random, your results will be very different from mine. So don’t worry about the actual numbers, rather about the concept.
n1 = Neuron()
print(n1.forward(x[0]), y[0])
print(n1.w, n1.b)In my case, the predicted answer was 0.84892235. This is a completely random value since our weight and bias are also random. The actual answer was supposed to be 8 (since 2 x 1 + 6 = 8). We’re off by about 7.15
The weights and bias value initialized are:
- w = -0.58040302
- b = 1.42932537
Of course, since we know what the actual weight and bias should be, we can tell that the weight needs to go up by about 2.58 and the bias needs to go up by about 4.57. But the network doesn’t know it. All it has is the predicted value and the actual value. We need to find a way to get the network to change its weight and bias based on how wrong it is.
Introducing the Mean Squared Error
In our previous answer, our predicted value was 0.8 and the real answer was 8. To figure out how wrong we are, we simply found out the difference. In reality, this isn’t a good way to figure out our “loss”.
Suppose we had run our network 10 times. Then we had found the difference and averaged it over to get an “average” estimate of the loss:
# pred is a list of 10 elements, from running a hypothetical network 10 times
pred = []
# Printing out the predicted and the actual answers
for i in range(len(pred)):
print(f'predicted: {round(pred[i], 2)}, actual: {y[i]}')
# Finding the average deviation from the real answers
(y - pred).mean()predicted: 14.23, actual: 8
predicted: 7.94, actual: 10
predicted: 21.32, actual: 12
predicted: 3.52, actual: 14
predicted: 20.4, actual: 16
predicted: 7.05, actual: 18
predicted: 17.02, actual: 20
predicted: 17.62, actual: 22
predicted: 31.64, actual: 24
predicted: 34.22, actual: 26
-0.4962847773238209Take a look at the predicted and the actual values. For some x values, they’re so far off. None of them are that close too. But our mean error appears to be just -0.49. What’s happening?
If our network is initialized completely randomly, you can expect that on average, the network underestimates the actual answer half of the time and overestimates the actual answer half of the time. But, if we simply find the difference and take an average of that, we’ll sort of be canceling out the positive and the negative losses. So our total loss appears to be very little.
We need to get rid of the signs. The first answer that comes to mind is simply to take the absolute value. While that is completely okay to do, in the future we’re going to take the derivative of that function. Unfortunately, the derivative of the absolute value function is undefined when x=0. You can see a sharp corner at this point:

You can see that both sides of the graph give different slopes when approaching the origin. So the absolute value function is out of the options. Only if there was another function that is smooth and approximates the absolute value function. Why not use the square function?
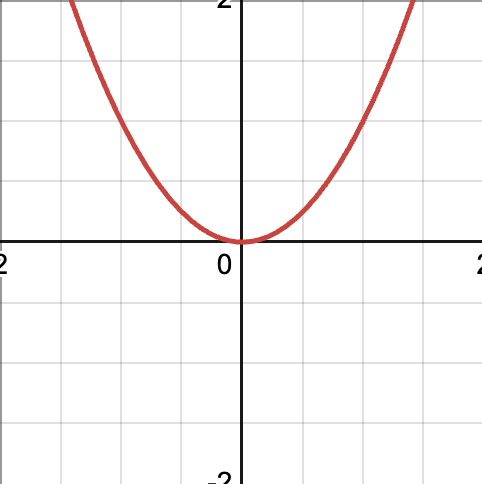
It looks kind of like the absolute value function, except it’s smooth. So the derivative is defined everywhere. Let’s implement that:
error = y - pred
squared_error = np.power(error, 2)
mean_squared_error = squared_error.mean()This is where we get our mean squared error. This is what we get if we replace the error with MSE:
predicted: 13.06, actual: 8
predicted: -2.3, actual: 10
predicted: 1.47, actual: 12
predicted: 4.16, actual: 14
predicted: 14.37, actual: 16
predicted: 14.91, actual: 18
predicted: 28.67, actual: 20
predicted: 15.7, actual: 22
predicted: 22.78, actual: 24
predicted: 29.89, actual: 26
52.83144416945561The new error value is much larger than the previous one (-0.49). This happens because squaring the differences between predicted and actual values makes all errors positive and larger, so they add up more significantly.
In mathematical notation, the function looks like the following:
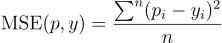
It’s just the averaging formula, but each term is the squared difference.
If we want to take the derivative of this formula with respect to y^\hat{y}y^, we can ignore the constant 1n\frac{1}{n}n1 and the summation part and just take the derivative of the squared difference part. Using chain rule, the answer is:

I’ll explain the importance of taking the derivative later.
We can implement MSE and its derivative in Python as:
def mse(a, y):
return np.power(a-y, 2).mean()
def mse_deriv(a, y):
return 2*(a - y) / len(a)So, we’re done with three steps:
- Initialize random weight and bias
- Process the input to get a predicted value
- Figure out how wrong we are based on the actual value
We have one last step:
- Update our weight and bias based off of how wrong we are
This last part requires some calculus. Let’s get started.
If we were to express our entire process in a single mathematical equation, it will look like this:

L represents our “loss” function. It basically is the formal term for “how wrong we are”. It is a function of the weight and bias. In the function we simply calculate wx+b , and then run it through the MSE function along with our y value.
Our next step is to figure out how much w and b need to change so that L(w, b) is “minimized”. This is known as an optimization problem in calculus. The formal term for what we’re about to do is known as “gradient descent”
Gradient Descent
Look at this equation again:
First of all, let’s make this equation a little more workable. Since the y value is always constant, we can sort of ignore it. Suppose we create a new function:
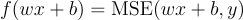
We do this just so we can write the original equation as this:

Now, we can ignore the y values and only work with wand b.
Try to image the graph of this function. Since it has two variables, it is a 3-dimensional graph. Let’s suppose it looks like this:

Our main job is to minimize the function L. Suppose you’re at a random point in the graph. This means that w and b have been randomly initialized. In the image, it is the black dot. Imagine placing a ball there and letting gravity move it around. It will swerve around the terrain until it finds a pit. Our job is to find that movement. In calculus, the gradient shows the direction and steepness of the slope. To find the lowest point of our error function, we move in the opposite direction of the gradient, like going downhill.”
The gradient is defined as follows:
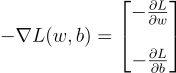
This means we calculate how the error changes with small increases in the weight (w) and the bias (b). We use the negative sign to move in the direction that reduces the error.
Since it is a single equation, finding the derivatives shouldn’t be difficult. To use the chain rule, we’ll need to introduce an intermediate variable:
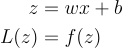
To find how changes in the weight (w) affect the error (L), we use the chain rule. First, we see how w affects the output (z), then how z affects the error. Combining these, we get:
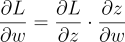
The equation basically says that to get the influence of w on L, you need to combine the influence of w on z, then the influence of z on L.
Similarly, you can find the partial derivative of L with respect to b:

Since L and z are related through the equation:
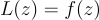
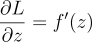
The partial of L with respect to z is just the derivative of the MSE function. We have already found it before.
Then, to find the partial of z with respect to b and w, we look at teh equation:

This is a linear equation, so it should be pretty simple:
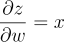

So, multiplying the terms together, we get:

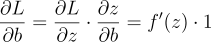
So, our gradient is:

If we just add this to our weight and bias, then we can get close to minimizing the loss.
Finally, we need a way to control how quickly we move down. Because if we subtract a really big vector, we might start jumping places. We want our descent to be iterative and slow so that we don’t waste time or miss the minimum. We do this through a learning rate. The learning rate (α) is just a number that we multiply with the gradient, to decrease its size.
We can implement this in Python now:
class Neuron:
def __init__(self):
# Initializing random weight and bias
self.w = np.random.randn(1)
self.b = np.random.randn(1)
def forward(self, x):
# Storing the x value for later use
self.x = x
# Equation of straight line
self.z = self.x * self.w + self.b
return self.z
def backward(self, pred, y, learning_rate):
# Getting the derivatives
dLdz = mse_deriv(pred, y)
dzdw = self.x
dzdb = 1
# These are the first and second terms of the gradient vector
dLdw = -dLdz * dzdw
dLdb = -dLdz * dzdb
# Updating our weight and bias
self.w += learning_rate * dLdw
self.b += learning_rate * dLdbTesting our code out:
# Initializing the neuron and the learning rate
n1 = Neuron()
learning_rate = 0.01
# Running the forward function and getting the error
pred = n1.forward(x[0])
e = mse(pred, y[0])
print(e)
# Updating the weight and the bias
n1.backward(pred, y[0], 0.01)
# Running the forward function again.
pred = n1.forward(x[0])
e = mse(pred, y[0])
print(e)If our code and math are correct, the second error should be smaller than the first. Here are my results:
42.583720984863774
39.24515725965046Indeed, the error has decreased. So it seems that our neuron is learning. We can now simply have the neuron run over all the data and see the result:
n1 = Neuron()
learning_rate = 0.01
for i in range(len(x)):
pred = n1.forward(x[i])
e = mse(pred, y[i])
print(e)
n1.backward(pred, y[i], learning_rate)66.62677307207422
94.98632400255632
105.91931437008931
83.46820591406723
38.46057551612359
6.393149346218136
0.008900618383414957
0.5454364287446387
0.15904926262193797
0.08605232722035641Look at that! The error decreased from 66 to almost 0. This single iteration over all the training data is known as an “epoch.” We can run the network over the data multiple times to improve accuracy:
n1 = Neuron()
learning_rate = 0.01
epochs = 10 # The training will run over the data 10 times
for epoch in range(epochs):
print(f'epoch number: {epoch}')
total_error = 0 # This is to calculate the eaverage error over all the data
# Running the training
for i in range(len(x)):
pred = n1.forward(x[i])
e = mse(pred, y[i])
total_error += e # Adding to the total error
n1.backward(pred, y[i], learning_rate)
# Getting the average erro
print('average MSE: ', total_error/len(x))epoch number: 0
average MSE: 39.23317004087497
epoch number: 1
average MSE: 4.570101564220641
epoch number: 2
average MSE: 4.25780521910065
epoch number: 3
average MSE: 3.966849539128853
epoch number: 4
average MSE: 3.6957762171681976
epoch number: 5
average MSE: 3.4432265990067306
epoch number: 6
average MSE: 3.207934873608693
epoch number: 7
average MSE: 2.988721728707433
epoch number: 8
average MSE: 2.7844884399412977
epoch number: 9
average MSE: 2.5942113639063704Now, if we look at the weight and the bias of the neuron, they should closely resemble 2 and 6. Here are the actual weight and bias:
w = 2.23323958, b = 3.52515427
Close, but not close enough. What if increase the number of epochs from 10 to 100:
w = 2.01224341, b = 5.87008833
Much closer! The more we train our neuron the better it gets.
To run the code, be sure to check out my notebook
Conclusion
Congratulations! You’ve just built a basic neural network with a single neuron from scratch. We’ve covered how to initialize the neuron, predict outputs, calculate errors, and update weights and biases using gradient descent.
In the next part of this series, we’ll take things up a notch by exploring how to create and train neural networks with multiple neurons organized into layers. This will allow us to tackle more complex problems and improve our network’s ability to make accurate predictions. Stay tuned for a deeper dive into constructing and optimizing multi-layer neural networks!